Overview
Linting is good. It reduces time spent finding bugs, reviewing pull requests, and enforcing conventions. It sets a better focus for maintainers than fighting about styles. And in its essence, it enforces best-practices.
Yet, linting is not always good. It becomes dangerous with the “linting trap”. Linting trap happens when linting tools enforce insecure code or code that’s hard to change. The trap is not necessarily set-up by the tools themselves as default, but by those who configure them.
This article gives you guidance for escaping linting traps in ESLint. This way, it protects your software from maintainability and security challenges. It does not discuss different subjective and aesthetic preferences. It considers two aspects as more prioritized than others:
- Smaller security vulnerability surface.
- Easier future changes.
ESLint is a linter released in 2013. It lints mainly JavaScript but it’s extensible to lint more (such as TypeScript 1 , JSX 2 or even YAML 3 ) with plugin support. Being a damn good linter made it the most popular tool in a short amount of time with 12 million downloads a week 4 . It’s used and recommended by Microsoft 5 , Facebook 6 and a lot of open-source projects. It does not lint before you choose your rules. Users often start with existing collections (baselines), and by trusting that there will be no traps.
Some style guides configure bad rules, and unknowingly force you into a linting trap. All traps stated here are enforced by Airbnb style guide. Dangerously, it’s the most popular rule collection, typically configured as default by development tools like React and Vue CLI. Its traps introduce maintainability and security risks to millions of projects weekly 7 . Other risky guides include standard , eslint-config-alloy , Facebook ( create-react-app , facebook/fbjs ), Canonical , Spotify , Wikimedia and XO among others. This guide highlights those traps, maps them to popular rule collections, and gives you justification to disable bad ESLint rules.
💡 I have released an open-source project,
eslint-config-disable-bad-rulesthat you can use to automatically turn off what you read here.
Traps
no-use-before-define
Disallow use of functions before they’re defined.
Enforced by
- Airbnb
- facebook/create-react-app
- Shopify
- Wikimedia
- Canonical
- eslint-config-standard
- eslint-config-alloy
- Spotify
- Alibaba
The trap
It leads to writing code that takes more time to understand, which leads to potential bugs.
This rule disables one of the best best-practices, breaking the Principle of least astonishment (POLA), or also known as the Principle of least surprise (PLS) 8 . The first time when the interested person opens a file, one would like to see what he/she expects, instead of scrolling to find it after uninteresting implementation details. It’s the same reason public methods should come before private methods. Per contra, this rule brings what’s least interesting to the top, and most to the bottom.
The order in code should start with the most expected function/definition of interest. This is typically achieved by sorting functions from high-level to low-level, or from declarative to imperative code.
The “from contract to implementation” mindset is also what empowers test-driven development, where developers write tests and thus contracts before the implementation.
Disable it because:
- Disabling saves time by helping to prevent reading a file until the bottom of the file to find out what it does.
- Disabling reduces the potential for bugs by communicating intent directly, because the key to tackling complexity is to abstract the problem at the highest level possible.
As an example, the main function of a class is its public members, thus its contract. If that class uses a lot of free functions and inner types for implementation details, this rule ensures that code will be on top of everything. It would cause confusion and time loss for the code reader.
Should this rule ever be enabled?
Enable it for legacy code that has unclear scoping, such as using old-school styles like var hoisting 9 .
arrow-body-style
Description
Enforces no braces where they can be omitted or require braces in arrow function body.
Enforced by
The trap
This rule has two options with two different behaviors: “always” and “as-needed”. “as-needed” is the default and enforced by rule-sets, and it’s the one that should be disabled.
Option “as-needed” enforces no braces where they can be omitted. This is enforced by Airbnb by default and the worst one. It’s redundant because braces help with making future changes easier by e.g. adding new lines such as console logging. It also helps in debugging by providing the ability to set granular breakpoints. Easier future changes are prioritized higher than style consistency in this guide.
Option “always” enforces braces around the function body without exception. Disabling is a matter of personal preference, rather than having more maintainable code with fewer problems. This option simply tells you to refactor from (person) => person.isYoung() to (person) => { return person.isYoung(); }. It aligns with the reason we disable “as-needed” option; it can lead to consistent but bloated code. It can be considered overkill for simple bodies (e.g. making a single call) that may not require it. Enabling/disabling this rule is outside this article’s scope.
The decision should be left to developer’s situational judgement.
Should this rule ever be enabled?
“as-needed” should never be enabled, “always” could be enabled to prioritize consistency or if the developers lack the ability to make choices based on analyzing what’s best for the current situation.
no-plusplus
Description
Disallow use of unary operators (++ and --).
Enforced by
The trap
You should disable this rule because unary operators are expressive and ensure type safety that reduces the attack surface.
The background of this rule comes from Douglas Crockford’s personal taste when he built JSLint (which was the biggest linting tool before ESlint took over). He found the syntax inexpressive 10 and that it would lead to faulty code. To which Airbnb guide agrees 11 . The exact reasons he lists (inexpressivity and faulty code) are the reasons why this rule should be disabled.
They are expressive. That’s the reason they are with us today with the same precedence, associativity, and semantics of their original syntax. They originally came way back from language B, made popular with C/C++, then spread to almost any other major language. They enable constructing standard for-i loops, and allow expressing post-decrement and post-increment operators. Apart from this syntax, it’s very tedious to write for loops.
They are safe. In JavaScript, ++ and -- guarantees type safety and always returns a number. But for +=1 the JIT can interpret it as a string. It increases security by providing a guard against potential injection attacks.
So why is this rule enabled then?
Airbnb argues that this rule helps problems caused by semicolon insertion 11 . To explain this, let’s take a look at an example:
x
++
y
This is parsed as x; ++y;, not as x++; y.
This causes ambiguity. But the linting tool should detect those bad codes specifically, not disable the whole syntax can cause it. On another note, this semicolon problem can only occur if semicolons are not enforced. And the rule
semi already enforces semicolons, which makes this scenario impossible. So if it’s enabled, this rule loses its point. But absurdly, this bad rule is enforced by
Airbnb , which already enforces semicolons, but not by
Standard , which does not use semicolons instead of the opposite 😀.
On the side of banning it, I heard discussions where this syntax is hard to read and learn. I don’t think it’s a valid argument. Unary operators are one of the first lessons that are being taught in programming lessons. And we can not solve the lack of knowledge by banning use of knowledge, but by teaching knowledge.
Aside from stylistic preference, this rule brings little to no value but disadvantages.
Should this rule ever be enabled?
Only if the following are true:
- You have a strong stylistic preference.
- Your code base does not enforce semicolons.
- Your coding convention bans using for-i loops.
- Developers do not write unit-tests for new code.
- Your team consists of developers that have no desire to learn fundamental programming concepts.
class-methods-use-this
Description
Enforce that class methods use this.
Enforced by
The trap
It does not let having functions without member access in favor of enforcing usage of static functions. It makes any kind of inheritance annoying, making developers feel guilty for doing the right things.
The idea is good. If it can be static; let it be static. But its implementation is so naive that it becomes a problem. It does not check those conditions where one has those functions to comply with an abstraction or a parent. That leads to issues like:
- Inheritance: Let’s say you have classes A and B, which both inherit from the same class. Class B might not use
this, but it can’t be static because A needsthis. - Interface realization: Interface X is implemented by classes A and B. Class B does not support functionality yet and throws an exception. It cannot be static because of the X interface. These issues occur both in the application code, and in the test code for stub/mock/spy classes.
- Protected method: A protected static function that’s made available to derived classes. The goal is not to provide access to the state, but to offer a reusable way of solving a task.
These patterns are not edge cases; they are common enough in software that takes advantage of object-oriented code that the rule becomes a destructive bottleneck rather than a helping hand.
Along with them, the rule destroys the Dependency Inversion Principle, which states 12 :
High-level modules should not import anything from low-level modules. Both should depend on abstractions (e.g., interfaces).
Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Because it does not let you have stateless services with interfaces, which is actually good practice due to the testability it provides. It makes it impractical to have a large unit-testable code base using dependency injection.
To be constructive, a good implementation would be checking if a method can be static if:
- It’s not implementing an interface.
- It’s not overriding abstract/virtual methods.
Another alternative would be using a lighter logic, such as just checking compliance for only private functions. ReSharper’s “ Member can be made static ” is a good working example of it.
But before a better implementation is in place, the rule should be turned off.
Should this rule ever be enabled?
Enable it only if you’re aiming for functional programming only, and you’re very strict about it. You would possibly still have clean code using mixins or composition instead of inheritance and interface realization.
no-param-reassign
Description
- Disallows reassignment of function parameters
- Disallow parameter object manipulation except for specific exclusions
Enforced by
The trap
Because it makes you write:
- Secure code
- Object-oriented code
Let’s start with secure code.
ESLint argues that this rule prevents future mistakes because developers can trust that parameter values will not mutate inside function 13 . It tries to manage change by not allowing change. Consequences of not having a change may lead to security vulnerabilities, which would have a greater impact on code than the trust of developers. The trust that should not be there in the first place.
A good security principle is that you should never trust user input data (which is the parameter), always validate it, but also sanitize it to put it in a form that would not lead to problems. Not doing so can lead to many security risks, such as privilege escalation or DoS attacks through deserialization and buffer-overflow errors. Enabling this rule may lead to improper input validation vulnerability.
Let’s look at an example:
function sendRequest(options) {
options = { ...DefaultOptions, ...options };
log('Sending request')
if(getRequest(options)) {
sendGetRequest(options);
}
...
}
We have an options object that comes from the user, then it’s filled with defaults, then later reused. Using a separate variable would lead to referring to the wrong options variable in the future. Because the developer expects it to present valid options, not incomplete ones. It’s easy to follow even though a parameter is mutated. But if we followed this linting rule, then we’d end up with something like this:
function sendRequest(options) {
const defaultedOptions = { ...DefaultOptions, ...options };
log('Sending request')
if(getRequest(defaultedOptions)) {
sendGetRequest(options);
}
...
}
Do you see the issue here? sendGetRequest(options) uses the wrong options object (instead of defaultedOptions). Because the new developer had the wrong expectations. There’s now increased complexity of two objects being there for the same reason for the rest of the code. It lightens the path for future bugs. There’s a single truth here, and that’s the options. Creating versions or variations of truth complicates its usage, because the developer must read and understand all the code to figure out which options he will use.
It’s true that some developers assume that a parameter is never assigned any value during a method’s run, and this wrong expectation may lead to a harder understanding of code. But it’s much more costly when some developers use invalidated/non-sanitized parameters due to security issues.
On the other hand, disabling this rule enables object-oriented code.
Mutating a member property in an object-oriented JavaScript is not a bad practice.
increaseAge(person, lastYear) {
const passedYears = new Date().getFullYear() - lastYear;
person.age += passedYears;
}
A setter in Person class in this example can validate the new age. This is perfectly valid object-oriented code that could be part of any best-practice patterns such as domain-driven design.
The biggest argument to enable this rule is to prevent a side effect: modifying arguments.
arguments is a special array-like object in JavaScript that gives access arguments using an index starting from zero. As an example, if we have a function that looks like function func1(x, y), then arguments[0] would equal to value of x and arguments[1] to value of y. Mutating those parameters mutates the arguments object. So if we do x=5 assignment in the function, it will lead to arguments[0]=5. It will then break code that rely on immutable arguments object.
However, using arguments object itself is anti-pattern and should be discarded completely. As of today, ESLint does not have a rule for that. The MDN (Mozilla Developer Network) recommends using
rest parameters over arguments
14 .
This rule enforces us to write code in a specific way to be able to achieve good harmony with code that’s bad anyway. Why shouldn’t we get rid of the bad code instead?
The real cause of complex code is not re-assigning the parameter values, but doing it in unexpected places. Deep inside if statements or at random places in a long function. It’s a code-smell. And a better lint rule could check for how deep and late the re-assignment occurs and alert on that.
So, avoiding re-assignment does not make your code better or easier to follow and refactor. Its side effect is the result of using bad and legacy code that should not exist to begin with. On the opposite, not using it may lead to future bugs, more complex code, and most notably: security vulnerabilities.
Should this rule ever be enabled?
Enable if:
- You work on a legacy code base that for some reason cannot be refactored to not use
argumentsobject. - You have complete test coverage of the code base.
import/prefer-default-export
Description
Require modules with a single export to use a default export.
Rule definition in importjs/eslint-plugin-import
Enforced by
The trap
It reduces developer productivity without adding any real value. On the opposite, it introduces problems with consistency and maintainability.
Code consistency. The code becomes more complex by using two different systems. Forcing developers to read and use both systems makes development less productive. It’s easier to follow one of the export systems instead of combining two that look like:
Single export system:
// Import using single export system import SingleExport from './single-exporter' // Export using single export system default export class ImportExport { ... }Multiple export system:
// Import one or multiple using multiple export system import { FirstExport } from './multiple-exporter' // Export both using multiple export system export class FirstExport { } export class SecondExport { }
Harder future changes. If there’s a single export today, but there’ll be multiple exports tomorrow, it’s much easier to just add a new import/export to multiple export system. For multiple export system, one must refactor all other usages. It makes large-scale refactoring very challenging. Also, with every default export you add, you create a technical debt to remove it once you have multiple exports.
Exporting more than necessary. A common workaround to the difficulties that this rule and single export system brings (such as harder future changes) is to export more than needed. Using something like default export namespace to export a whole namespace or similar bigger modules for simpler import patterns in the future. This workaround is an anti-pattern led by the rule (and single export system), and structuring those big modules is considered red-flag by TypeScript
16 . The code is easier to follow when you only express the least you want. Some also argue that with default modules you will lose some tree-shaking
17 and have slower access to imports
18 , but that’s pretty much an invalid argument on modern computers using modern tools.
Less tooling support. With named exports, you get auto-complete when importing. It provides more recoverability through whether a module exports what you want or not.
So why is this rule here? There’s only one real reason: “old habits”.
ECMAScript has two module systems. Something that’s not typically seen in other programming languages. The reason default exports were standardized was to please people from CommonJS and AMD worlds. It had nothing to do with the system being superior, or because it’s more cosmetic to the eye. It’s just politics and “old habits”.
During design discussions, Andreas Rossberg argued 15 :
Some want modules in the conventional sense, as encapsulated namespaces with named exports, which you can import and access qualified or unqualified, and where imports are checked. Some want modules in the specific pre-ES6 JavaScript style, where they can be any arbitrary JS value, and in the good old JavaScript tradition that checking doesn’t matter. The current design (including the newest suggestions for imports) seems to please neither side, because it tries to be the former semantically, but wants to optimise for the latter syntactically. The main outcome is confusion.
Both filled the gap when support for modules was missing in ECMAScript. But today, we should let the legacy die and focus on productivity.
Should this rule ever be enabled?
Enable it if you are working in a team that resists change and cannot let the past be the past.
No for-of
Description
Disallows using for .. of loops.
Implemented using no-restricted-syntax such as:
"no-restricted-syntax": ["error", "ForOfStatement"]
Enforced by
The trap
Disabling it has clear benefits. But there are also valid reasons why this rule exists, such as:
- Functions facilitating functional programming such as
map,filter, etc. can often communicate intent cleaner with better syntax. - Immutability of functions can safeguard against mistakes.
.forEachfunction allows what for-of statement cannot, such as using nested functions.
But these benefits do not weigh out the benefits of never using for-of statements based on the priorities of these guides: security and easier future changes. Let’s look at those:
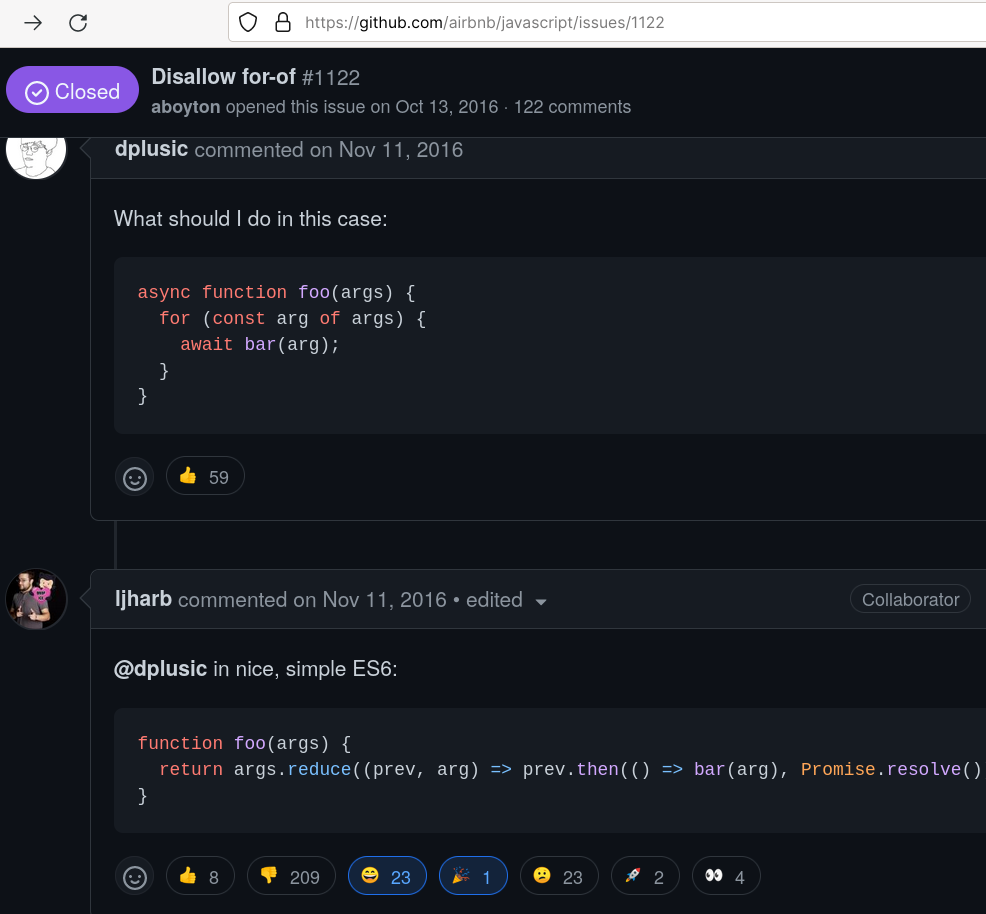
Cleaner asynchronous code. But the functional approach is not always the easiest to read, and there are cases where for-of loops shine. For-of loops empower clean asynchronous programming, which is best-practice itself. Here’s an example, ironically taken from a discussion where Airbnb maintainer arguments in favor of not using for-of loops
19 :
Memory and CPU-efficient. For-of loops are also favored in speed and memory usage. For-of loops are faster according to some benchmarks
20 , but these kinds of benchmarks do not necessarily show your precise use-cases. Fast, and also efficient; for-of loops take less space than using a functional alternative like map and reduce that returns a new list of references/values. These advantages are not game changers, though they often lack a significant impact.
Generator syntax. For-of loops allows generator syntax
21 which allows lazy-evaluation
22 where the data source yields what’s needed, no more. It’s uncommon but handy for clean and fast code when possible. Asynchronous iterators using
for await...of simplifies reading from I/O streams drastically.
Exiting. One other benefit is that for-of loops allow you to break out of it. You can return once you’re done before the iteration ends. You lose the ability to short circuit iterations without for loops. Breaks are GoTo statements
23 that indicate code smell. find, includes, some, every provide more elegant ways, but not at all times. Like the following loop that iterates until what’s needed breaks once the need disappears:
function findOs(userAgent, detectors) {
for (const detector of detectors) {
const os = detector.detect(userAgent);
if (os !== undefined) {
return os;
}
}
return undefined;
}
This could be written with a way to stop execution, but not without
side effects (mutating another object). If we rewrite it using e.g. some:
function findOs(userAgent, detectors) {
let os = undefined;
detectors.some((detector) => {
os = detector.detect(userAgent);
return os !== undefined;
});
return os;
}
We now have written an even more problematic code:
- We convert a side effect where the variable
osis mutated to core logic. - Furthermore, we throw away the result of
somefunction, which is another bad practice.
One could rewrite it using every, or go crazy with find, reduce and map. But all would be either less efficient or have side effects, and most essentially, it would not communicate intent better than for-of loops.
Equally functional. A common misconception is that using alternatives to for-of loops makes your code functional. They do not always include side effects, and .forEach is as non-functional as for-of loops.
So there are times they are better alternatives, and times they are not. This must be left to developers’ situation-based judgement and not dictated for all cases.
Should this rule ever be enabled?
When you target older browsers that do not support for of loops (ES5 and below) and your code is not pollyfilled. Otherwise, there’s no room for this rule in a modern application until a crazy guy starts paying all developers to quit using it.